This blog post will provide you with hands-on experience with Kubernetes affinity and anti-affinity. We will test node affinity as well as POD affinity for „soft“ and „hard“ rules.
Introduction
Node affinity and anti-affinity are similar to node selectors and taints, respectively:
- Alike node selectors, node affinity rules ask the Kubernetes scheduler to spin up the PODs on nodes with certain labels defined. The most important difference between node selectors and node affinity is that the latter support logical operators like AND and OR.
- Node anti-affinity will try to avoid nodes with certain labels, which is similar to node taints that repel PODs without tolerations from running on that node.
POD affinity and anti-affinity allow for following new functionalities:
- The Kubernetes scheduler will try to run PODs with POD affinity rules on nodes or failure domains that are already hosting PODs with certain labels.
This makes sense, if certain PODs intensively communicate with other PODs, and therefore should be located close to each other. - The scheduler will try to avoid running PODs with POD anti-affinity rules on nodes or failure domains that are already hosting PODs with certain labels.
Consider running a cluster application in PODs: in this case, it makes sense to keep PODs of the same cluster on different failure domains: e.g. if a cloud region becomes unavailable, with anti-affinity you can make sure that some of the PODs of the cluster are still available, and therefore the cluster is kept operational.
Step 0: Preparations
Step 0.1: Access the Kubernetes Playground
We use the CKA Killerkoda playground. It comes with two nodes, a master and a slave.
Step 0.2 (optional): Configure auto-completion
The Katacoda Kubernetes Playground has defined the alias and auto-completion already. Only in case you are running your tests in another environment, we recommend issuing the following two commands:
alias k=kubectl source <(kubectl completion bash)
Auto-completion for the alias k for can be enabled with the following command:
source <(kubectl completion bash | sed 's/kubectl/k/g') # or alternatively: complete -F __start_kubectl k
Once this is done, k g<tab> will be auto-completed to k get and k get pod <tab><tab> will reveal the name(s) of the available POD(s).
Step 0.3 (required): Untaint the master
As we have learned in the previous blog post, the default taints on the master prevent „normal“ PODs with no tolerations to be scheduled on the master. For testing affinity rules, we need two worker nodes as a minimum. Since the Katacoda Kubernetes Playground provides us with a master and a single worker node only, we need to remove the taint from the master, so we can use it similar to normal worker nodes:
# check before: kubectl describe nodes | egrep "Name:|Taints:" Name: controlplane Taints: node-role.kubernetes.io/control-plane:NoSchedule Name: node01 Taints: <none> # remove taint: kubectl taint node controlplane node-role.kubernetes.io/master- node/master untainted # check the taints after removal: kubectl describe nodes | egrep "Name:|Taints:" Name: controlplane Taints: <none> Name: node01 Taints: <none>
Task 1: Use Node Selector to place a POD on a specific Node
We have two possibilities to control the location of a POD: node selectors and node affinity rules. Let us start with the simpler node selector:
Step 1.1: Check Labels
Each node is assigned labels that can be used to manipulate, where a POD will be scheduled. Let us check the labels on our two nodes:
k get nodes --show-labels NAME STATUS ROLES AGE VERSION LABELS controlplane Ready control-plane 9d v1.25.3 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=controlplane,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers= node01 Ready <none> 9d v1.25.3 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node01,kubernetes.io/os=lin
Step 1.2: Create a YAML file with nodeSelector
PODs cannot be changed after creation, and we have not found any possibility to specify the nodeSelector in the k run command. Therefore we create a YAML file with the nodeSelector
k run node-selector-pod --image nginx --dry-run=client -o yaml > node-selector-pod.yaml
Then let us edit the file and add the parts in blue:
# node-selector-pod.yaml
apiVersion: v1
kind: Pod
metadata:
labels:
run: node-selector-pod
name: node-selector-pod
spec:
containers:
- image: nginx
name: node-selector-pod
nodeSelector:
kubernetes.io/hostname: controlplaneThere, we have chosen the hostname label to specify that the POD should be located on the controlplane.
Step 1.3: Create POD from the YAML File
Now we can create the POD:
k create -f node-selector-pod.yaml pod/node-selector-pod created
Step 1.4: Check the location of the POD
We now can verify that the POD was indeed scheduled on the controlplane node:
k get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES node-selector-pod 0/1 ContainerCreating 0 6s <none> controlplane <none> <none>
Task 2: Node Affinity „hard“ Rule Example
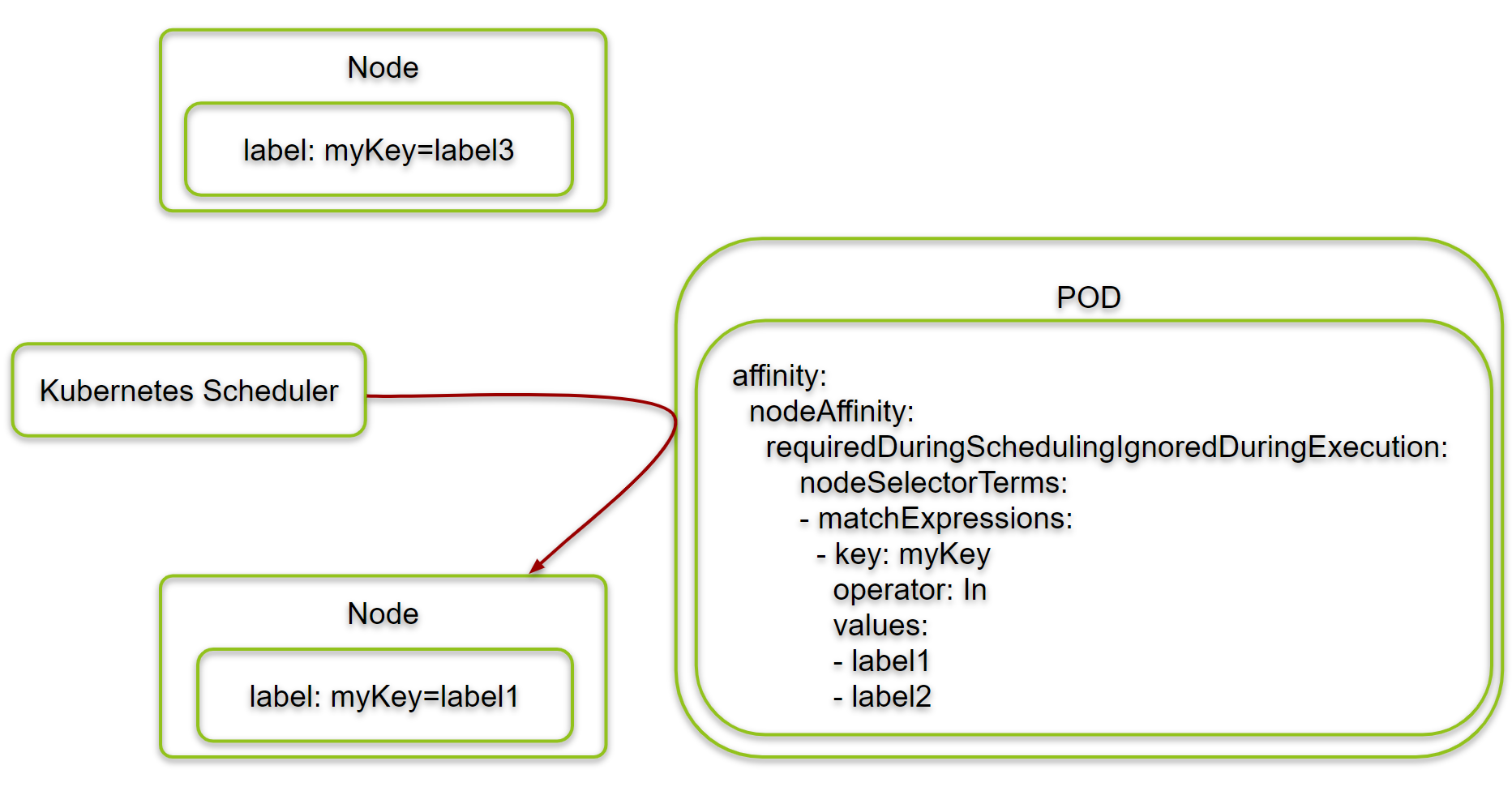
Step 2.1: Create a POD with Node Affinity Rule
Let us now create a deployment with a POD spec with a node affinity rule:
cat <<EOF | kubectl create -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: myKey
operator: In
values:
- label1
- label2
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
EOF
# output:
deployment.apps/nginx-deployment createdYou will find the affinity rule in blue.
Since neither label1 nor label2 is defined on any node, the PODs have a Pending status:
kubectl get POD -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-deployment-8c64b4cf7-plkd9 0/1 Pending 0 6m20s <none> <none> <none> <none> nginx-deployment-8c64b4cf7-rb52g 0/1 Pending 0 6m20s <none> <none> <none> <none>
The reason can be found in the events:
kubectl describe pod nginx-deployment-8c64b4cf7-plkd9 | grep Events: -A 20 Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 67s (x7 over 8m18s) default-scheduler 0/2 nodes are available: 2 node(s) didn't match node selector.
Interestingly, the event message is identical to the one we find with nodeSelector rules in such a situation: 0/2 nodes are available: 2 node(s) didn't match node selector.
Step 2.2: Create a matching Label on the Master Node
Now we set the label myKey=label2 on the master:
kubectl label nodes master myKey=label1 node/master labeled
Immediately thereafter, the PODs enter the ContainerCreating and Running status:
kubectl get POD -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-deployment-8c64b4cf7-plkd9 0/1 ContainerCreating 0 15m <none> master <none> <none> nginx-deployment-8c64b4cf7-rb52g 0/1 ContainerCreating 0 15m <none> master <none> <none>
Step 2.3: Remove the Label
For checking, what happens with running PODs, if a label is removed, let us do so now:
kubectl describe nodes master | grep myKey
myKey=label2
kubectl label nodes master myKey-
node/master labeled
kubectl describe nodes master | grep myKey
<no output>Step 2.4: Check the POD Status
Now we can see that the PODs are still running on the master:
kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-deployment-8c64b4cf7-plkd9 1/1 Running 0 43m 10.32.0.5 master <none> <none> nginx-deployment-8c64b4cf7-rb52g 1/1 Running 0 43m 10.32.0.4 master <none> <none>
This is meant with the second part of the requiredDuringSchedulingIgnoredDuringExecution mode: the node affinity rule is irrelevant for PODs that are up and running on a node. Only new nodes will enter the Pending state:
kubectl scale deployment nginx-deployment --replicas=3 deployment.extensions/nginx-deployment scaled kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-deployment-8c64b4cf7-plkd9 1/1 Running 0 48m 10.32.0.5 master <none> <none> nginx-deployment-8c64b4cf7-rb52g 1/1 Running 0 48m 10.32.0.4 master <none> <none> nginx-deployment-8c64b4cf7-w4gk8 0/1 Pending 0 4s <none> <none> <none> <none>
Task 3: Node Affinity „soft“ Rule Example
In this task, we will show the difference between the two modes
- requiredDuringSchedulingIgnoredDuringExecution
- preferredDuringSchedulingIgnoredDuringExecution
We have seen above that the first mode is a hard requirement during the time the PODs are scheduled: i.e. PODs that do not find a matching label will enter the Pending status.
Step 3.1: Remove Label from Master, if present
We now will make sure the label of the master does not match:
kubectl label nodes master myKey-
Step 3.2: Create „soft“ Affinity Rule
However, what happens to PODs that have a „soft“ node affinity rule preferredDuringSchedulingIgnoredDuringExecution? For testing this, let us edit the deployment corresponding line
kubectl edit deploy nginx-deployment
and change the blue part as depicted below:
apiVersion: apps/v1
...
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1 # <----- added
preference: # <----- replaced: nodeSelectorTerms -> preference
matchExpressions: # <----- replaced array by map (removed "-")
- key: myKey
operator: In
values:
- label1
- label2
...
# output:
deployment.apps/nginx-deployment editedThe syntax for node affinity rules with preferredDuringSchedulingIgnoredDuringExecution is quite a bit different from the one with requiredDuringSchedulingIgnoredDuringExecution:
- we need to replace the nodeSelectorTerms by preference.
- We had to add a weight parameter in the range of 1 to 100. For each scheduling requirement like resource constraints, and matching preference expressions, the scheduler adds the weight to the node. The node with the highest sum of weights is preferred.
- Moreover, the
matchExpressionspart is a map and not a list of maps anymore. This is, why the minus sign beforematchExpressionspart had to be removed.
Step 3.3: Verify that new PODs are launched
You will see that there is a rolling update of the POD:
kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-deployment-795c767956-j4wwt 1/1 Running 0 65s 10.40.0.1 node01 <none> <none> nginx-deployment-795c767956-z2xvp 0/1 ContainerCreating 0 18s <none> master <none> <none> nginx-deployment-8c64b4cf7-ph95r 0/1 Pending 0 4m37s <none> <none> <none> <none>
Therefore, new PODs are replacing the old, Pending PODs. After two minutes or so, the new PODs should be up and running:
kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx-deployment-795c767956-j4wwt 1/1 Running 0 15m 10.40.0.1 node01 <none> <none> nginx-deployment-795c767956-z2xvp 1/1 Running 0 14m 10.32.0.2 master <none> <none>
Task 4: POD (Anti-) Affinity „hard“ Rule Examples
POD affinity controls, which node is preferred based on labels of other PODs already running on the node rather than based on labels on nodes.
Step 4.1 Untaint the master
We make sure that the master is not tainted again, so we allow PODs to run on the master. We redo this now since we want the tasks to be independent of each other
# remove taint: kubectl taint node master node-role.kubernetes.io/master- node/master untainted
Step 4.2: Create a POD with an affinity towards app=nginx
We now create a second deployment:
cat <<EOF | kubectl create -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx2
spec:
replicas: 20
selector:
matchLabels:
app: nginx2
template:
metadata:
labels:
app: nginx2
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: kubernetes.io/hostname
labelSelector:
matchExpressions: #<---- unlike nodeSelectorTerms in case of nodeAffinity, this is not a list, so the minus sign is missing here
- key: app
operator: In
values:
- nginx
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
EOF
# output:
deployment.apps/nginx2 createdSince we have chosen the affinity rule as a hard requirement (requiredDuringScheduling…), and no nginx app is available yet, all PODs remain Pending:
kubectl get pods NAME READY STATUS RESTARTS AGE nginx2-5f99855798-2pcqn 0/1 Pending 0 2m2s nginx2-5f99855798-52d2j 0/1 Pending 0 2m1s nginx2-5f99855798-5b7fd 0/1 Pending 0 2m1s nginx2-5f99855798-842kn 0/1 Pending 0 2m1s nginx2-5f99855798-8mdgb 0/1 Pending 0 2m1s ...
Step 4.3: Run a POD with app=nginx via Deployment
However, if we create a POD with app=nginx label, we expect the PODs to be launched:
# run a POD with a label kubectl create deployment --image=nginx nginx
This will create a POD with label app=nginx (among others):
kubectl get pod -o wide --show-labels
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
nginx-54f85c574b-rzdjc 1/1 Running 0 12m 10.44.0.2 node01 <none> <none> app=nginx,pod-template-hash=54f85c574bStep 4.4: Verify that the dependent PODs are launched on the same node
And yes, the PODs are created and finally reach the Running state:
kubectl get pods NAME READY STATUS RESTARTS AGE nginx-65f88748fd-g5mbs 0/1 ContainerCreating 0 3s nginx2-5f99855798-2pcqn 0/1 ContainerCreating 0 2m10s nginx2-5f99855798-52d2j 0/1 Pending 0 2m9s nginx2-5f99855798-5b7fd 0/1 Pending 0 2m9s ...
Because the POD with label app=nginx is located on node01 is started on node01, all nginx2 PODs are launched on node01 as well:
kubectl get pods -o wide --show-labels NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS nginx-65f88748fd-g5mbs 1/1 Running 0 7m8s 10.40.0.9 node01 <none> <none> app=nginx,pod-template-hash=65f88748fd nginx2-5f99855798-2pcqn 1/1 Running 0 9m15s 10.40.0.1 node01 <none> <none> app=nginx2,pod-template-hash=5f99855798 nginx2-5f99855798-52d2j 1/1 Running 0 9m14s 10.40.0.19 node01 <none> <none> app=nginx2,pod-template-hash=5f99855798 nginx2-5f99855798-5b7fd 1/1 Running 0 9m14s 10.40.0.20 node01 <none> <none> app=nginx2,pod-template-hash=5f99855798 ...
The affinity rule has made sure that the PODs are started on the same node as the POD with app=nginx.
Step 4.5: Create a POD with an anti-affinity towards app=nginx
Now let us test anti-affinity. We assume that a POD with app=nginx is running on node01 already. Let us start a POD with anti-affinity towards this label:
cat <<EOF | kubectl create -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: anti-nginx
spec:
replicas: 2
selector:
matchLabels:
app: anti-nginx
template:
metadata:
labels:
app: anti-nginx
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: kubernetes.io/hostname
labelSelector:
matchExpressions: #<---- unlike nodeSelectorTerms in case of nodeAffinity, this is not a list, so the minus sign is missing here
- key: app
operator: In
values:
- nginx
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
EOF
# output:
deployment.apps/anti-nginx createdWe can see, that the POD with app=nginx is running on node01, while the PODs that want to avoid the latter are running on the master:
kubectl get pod -o wide --show-labels | egrep "anti|app=nginx," anti-nginx-7698b848b9-tgj4l 1/1 Running 0 2m22s 10.32.0.2 master <none> <none> app=anti-nginx,pod-template-hash=7698b848b9 anti-nginx-7698b848b9-vh977 1/1 Running 0 2m22s 10.32.0.3 master <none> <none> app=anti-nginx,pod-template-hash=7698b848b9 nginx-65f88748fd-vg8w4 1/1 Running 0 6m8s 10.40.0.1 node01 <none> <none> app=nginx,pod-template-hash=65f88748fd
Step 4.6: Create self-repelling PODs (hard, „Highlander“ Case)
We can also create a deployment with PODs that repel each other like follows:
cat <<EOF | kubectl create -f - apiVersion: apps/v1 kind: Deployment metadata: name: highlander spec: replicas: 1 selector: matchLabels: app: highlander template: metadata: labels: app: highlander spec: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - topologyKey: kubernetes.io/hostname labelSelector: matchExpressions: #<---- unlike nodeSelectorTerms in case of nodeAffinity, this is not a list, so the minus sign is missing here - key: app operator: In values: - highlander containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80 EOF # output: deployment.apps/highlander created
We have called it „highlander“ because there can only be one per node.
k get pods -o wide --show-labels | egrep "NAME|highlander" NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS highlander-77b4b44dfb-zq59s 1/1 Running 0 69s 10.32.0.4 master <none> <none> app=highlander,pod-template-hash=77b4b44dfb
The first highlander happens to be running on the master. Now let us scale the highlander to two:
kubectl scale deploy highlander --replicas=2 deployment.extensions/highlander scaled kubectl get pods -o wide --show-labels | egrep "NAME|highlander" NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS highlander-77b4b44dfb-wvgzp 1/1 Running 0 3s 10.40.0.22 node01 <none> <none> app=highlander,pod-template-hash=77b4b44dfb highlander-77b4b44dfb-zq59s 1/1 Running 0 3m3s 10.32.0.4 master <none> <none> app=highlander,pod-template-hash=77b4b44dfb
We see above that the second highlander is running on node01. The second highlander has found a world of its own.
Now let us try, to scale the highlanders to three:
kubectl scale deploy highlander --replicas=3 deployment.extensions/highlander scaled kubectl get pods -o wide --show-labels | egrep "NAME|highlander" NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS highlander-77b4b44dfb-qh5fv 0/1 Pending 0 5s <none> <none> <none> <none> app=highlander,pod-template-hash=77b4b44dfb highlander-77b4b44dfb-wvgzp 1/1 Running 0 99s 10.40.0.22 node01 <none> <none> app=highlander,pod-template-hash=77b4b44dfb highlander-77b4b44dfb-zq59s 1/1 Running 0 4m39s 10.32.0.4 master <none> <none> app=highlander,pod-template-hash=77b4b44dfb
Since we have chosen a „hard“ anti-affinity requirement, the third highlander cannot find a node, where it can run, so it will be kept in pending status.
Task 5: POD Affinity „soft“ Rule Example
In order to make Task 4 independent of the other tasks, we repeat un-tainting the master:
Step 5.1 Untaint the master
We make sure that the master is not tainted, so we allow PODs to run on the master. We redo this now since we want the tasks to be independent of each other
# remove taint: kubectl taint node master node-role.kubernetes.io/master- node/master untainted
Step 4.2: Create self-repelling PODs („electron“ example)
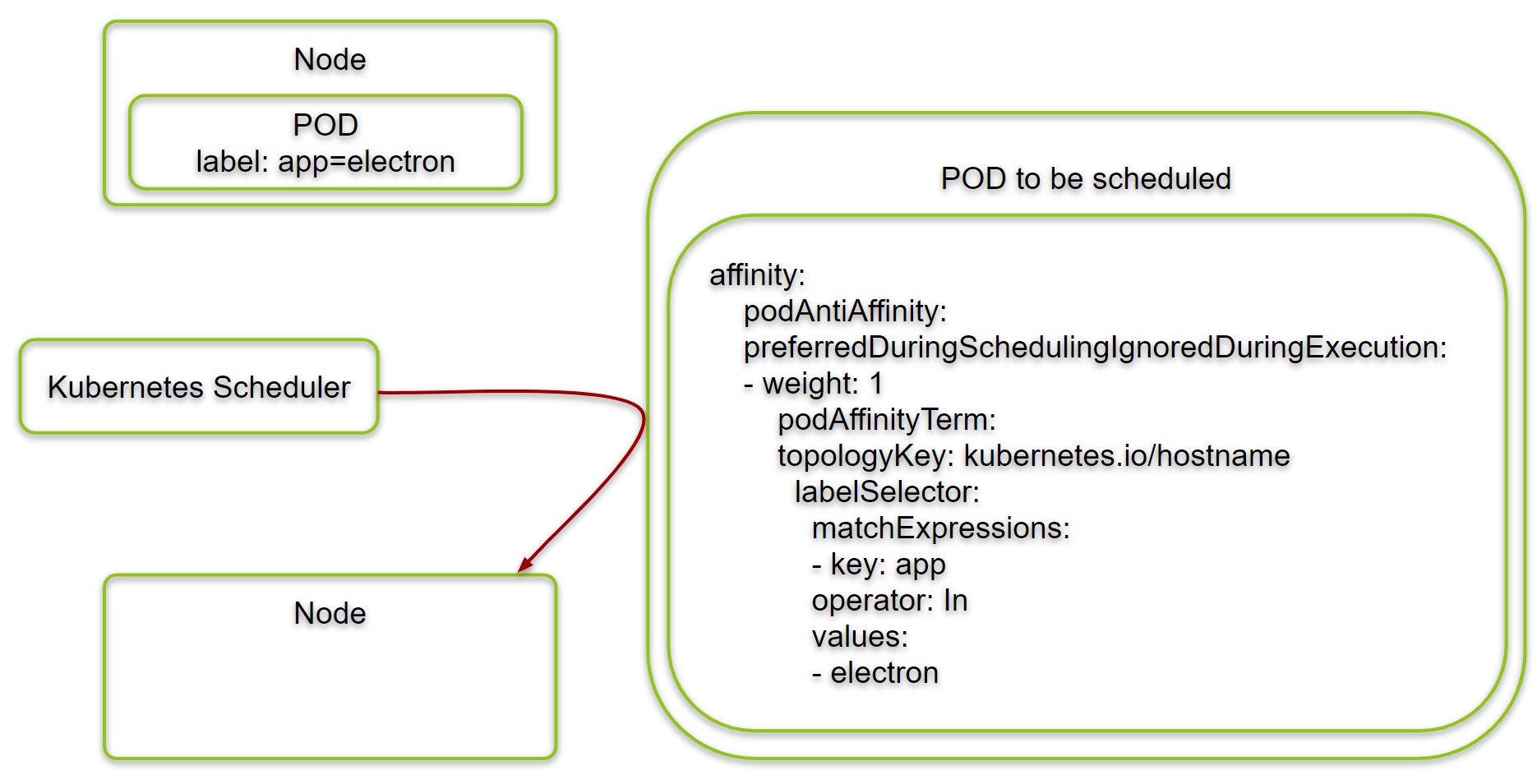
Now, let us do the same with a soft requirement: we create a deployment with PODs that repel each other, but this time in preferredDuringSchedulingIgnoredDuringExecution mode:
cat <<EOF | kubectl create -f - apiVersion: apps/v1 kind: Deployment metadata: name: electron spec: replicas: 1 selector: matchLabels: app: electron template: metadata: labels: app: electron spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 podAffinityTerm: topologyKey: kubernetes.io/hostname #<---- moved under podAffinityTerm labelSelector: #<---- moved under podAffinityTerm matchExpressions: - key: app operator: In values: - electron containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80 EOF # output: deployment.apps/electron created
We have renamed the PODs from „highlander“ to „electron“ since there can be more than one POD per node. However, they still repel each other.
kubectl get pods -o wide --show-labels | egrep "NAME|electron"
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
electron-78df676988-74hmr 1/1 Running 0 32s 10.32.0.2 node01 <none> <none> app=electron,pod-template-hash=78df676988The first electron happens to be running on the node01.
Step 5.3: Verify that the second POD is placed on another Node than the first POD
Now let us scale the electron to two:
kubectl scale deploy electron --replicas=2 deployment.extensions/electron scaled kubectl get pods -o wide --show-labels | egrep "NAME|electron" NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS electron-78df676988-74hmr 1/1 Running 0 2m15s 10.32.0.2 node01 <none> <none> app=electron,pod-template-hash=78df676988 electron-78df676988-nx89v 1/1 Running 0 25s 10.40.0.1 master <none> <none> app=electron,pod-template-hash=78df676988
The second electron is running on the master since it has been repelled from node01, where an electron is located already.
Step 5.4: Verify that the Rule is „soft“
Now let us try, to scale the electrons to three:
kubectl scale deploy electron --replicas=3 deployment.extensions/electron scaled kubectl get pods -o wide --show-labels | egrep "NAME|electron" NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS electron-78df676988-74hmr 1/1 Running 0 4m26s 10.32.0.2 node01 <none> <none> app=electron,pod-template-hash=78df676988 electron-78df676988-db6f5 1/1 Running 0 23s 10.32.0.3 node01 <none> <none> app=electron,pod-template-hash=78df676988 electron-78df676988-nx89v 1/1 Running 0 2m36s 10.40.0.1 master <none> <none> app=electron,pod-template-hash=78df676988
Since we have chosen a „soft“ anti-affinity requirement, the third electron can find its place on node01 again. Unlike the highlander case above, the POD does not remain in pending status.
Summary
Kubernetes Affinity and Anit-Affinity rules provide us with a rich set of controls, on which node a POD will be launched. Node (anti-) affinity rules allow the scheduler to choose the PODs location based on node labels, while for POD (anti-) affinity rules, the scheduler takes into account, which PODs are already running on a node.
There are two flavors of (anti-) affinity rules: a „hard“ rule (requiredDuringScheduling…) and a „soft“ rule (preferredDuringScheduling…). The latter will try to optimize the POD location based on the rule, but it will still launch the POD on a node, even if the rule cannot be met. On the other side, the hard rule is more strict and might keep a POD in pending status, as long as the rule cannot be met. Both types of rules will be ignored during execution. However, for node selectors, there are plans to provide a requiredDuringSchedulingRequiredDuringExecution version in the future. This kind of affinity rule will affect already running PODs, similar to taints with the „NoExecute“ effect.