 Ever since I had bought a Western Digital My Cloud System with 4 TB of Backup space, I had problems with it: after some hours, the system was unreachable over the network. Several firmware upgrades later the problem has aggravated, and the system was reachable only for 10 to 20 minutes after each power cycle.
Ever since I had bought a Western Digital My Cloud System with 4 TB of Backup space, I had problems with it: after some hours, the system was unreachable over the network. Several firmware upgrades later the problem has aggravated, and the system was reachable only for 10 to 20 minutes after each power cycle.
In this little blog, I summarize the measures I have taken to get it back to life.
Symptoms
A deeper analysis with Wireshark software has shown that the system is still up and running, but it was sending TCP RST back, when trying to connect to the Web Interface. Also backing up data was not possible anymore. Removing and re-attaching the power cable has helped, but no longer then 10 to 20 minutes. Then I have seen the same symptoms again.
Searching for a working solution via Google was in vain, so I thought, I have to throw away the system and buy something better. However, I have given it a last chance and I have done the following:
Step 1: Remove and re-attach the power cable
Step 2: Connect to the Web interface (is possible ~10 to 20 minutes after powering up).
Step 3: Enable SSH root access
Step 4: Connect via SSH, and change the default password to your individual password
Root Cause:
After 10 or 20 minutes, I have seen the same symptoms again: the web interface is sending Reset messages. However, the SSH connection was still up and running. This has helped me to figure out the problem.
top (hitting M will sort the entries by Memory) has shown, that the system was overwhelmed with respect to memory: before I have „repaired“ my system, the total memory used was around 100% of the physical memory (only 256 MB!) and another 50-70% of the Swap (500 MB). The heavy swapping has caused the system being unresponsive. The hard disks were continuously working quite audible.
CPU was about Okay, so this was not the problem.
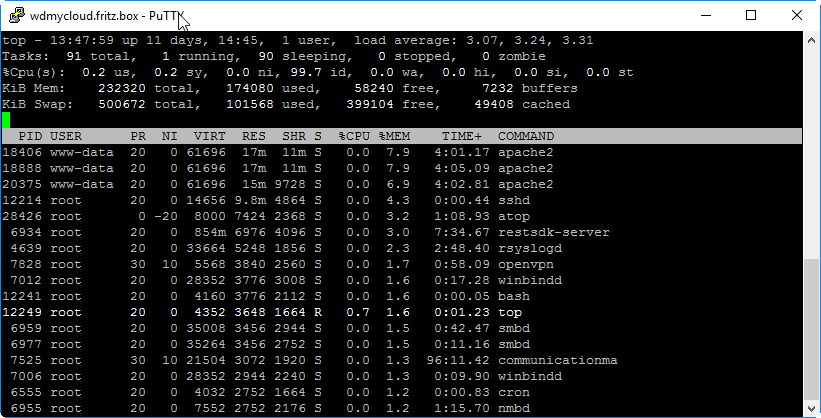
I could see that apache2 was running 10 times and each of those have occupied 8% of the memory, summing up to 80% of the available memory. As you can see above, switching off 7 of those 10 apache2 process were the key to success; a solution I have not found anywhere in the forums discussing the exact same unreachability symptoms with WD My Cloud. However, I have found this StackOverflow question asking, why there are so many apache processes running. The answer: „Check your httpd.conf for MinSpareServers, MaxSpareServers and ServerLimit“.
Still, it was not so easy to find the location, where those variables are defined on WD My Cloud. For WD My Cloud, it is not defined on /etc/apache2/apache2.conf as seems to be the case for most other Apache2 servers. A search has revealed the location:
WDMyCloud:~# grep -iR MaxSpareServers /etc 2>/dev/null /etc/apache2/mods-available/mpm_prefork.conf:# MaxSpareServers: maximum number of server processeshich are kept spare /etc/apache2/mods-available/mpm_prefork.conf: MaxSpareServers 10 /etc/apache2/mods-enabled/mpm_prefork.conf:# MaxSpareServers: maximum number of server processes wch are kept spare /etc/apache2/mods-enabled/mpm_prefork.conf: MaxSpareServers 10
And here, we find a confirmation: on WD My Cloud, I need to edit the values on /etc/apache2/mods-available/mpm_prefork.conf
This is, where I have changed the value from 10 to 3:
Resolution of the Problem
Step 5: Reduce the number of Apache2 Processes
As root, edit the file /etc/apache2/mods-available/mpm_prefork.conf.
Before the change, I have found following relevant content in the file:
StartServers 2
MinSpareServers 2
MaxSpareServers 10
MaxRequestWorkers 10
MaxConnectionsPerChild 10000
I have changed this to:
StartServers 2
MinSpareServers 2
MaxSpareServers 3
MaxRequestWorkers 3
ServerLimit 3
MaxConnectionsPerChild 10000
I have read somewhere, that the ServerLimit should have the same value as MaxSpareServers, so I have added it to the configuration (I have not tested without this entry, so it may be that it has no effect).
Step 6: restart apache
Restart Apache Server with
service apache2 restart
Check the memory consumption e.g. with top. It should have improved by now.
Step 7 (optional): Switch off additional services
You can switch off some of additional services you do not need for your WD My Cloud. In my case, I have chosedn a quick and dirty way of doing this by renaming following files:
mv /etc/init.d/twonky /etc/init.d/twonky.orig mv /etc/init.d/wdmcserverd /etc/init.d/wdmcserverd.orig mv /etc/init.d/wdnotifierd /etc/init.d/wdnotifierd.orig mv /etc/init.d/wdphotodbmergerd /etc/init.d/wdphotodbmergerd.orig
However, this is not needed, I think, and furthermore, it leads to error messages on the Windows backup client that a backup destionation was not found. Anyway, I have kept it this way, because the backup works fine, even though this error message pops up from time to time…
Step 8 (needed only, if step 7 was performed before):
reboot
DONE!
Result
Since then, the system is working silently (no more audible disk swapping) and reliably. It is up and running for more than 11 days now; continuous backup as well as the Web Interface is working fine, the the web portal’s responsiveness is much higher than ever before.
I hope this will help someone out there as well.
P.S.: I have included this information also in this forum post. The other forum posts discussing similar issues (e.g. here, here and here) were closed, so I could not add the information there.